We now turn to a discussion of some of the limitations and problems associated with describing abstraction.
Figure captions vs. animation to communicate abstraction. To ease the recognition of abstraction techniques, animation can be employed to interpolate between the original values and the values resulting from the application of abstraction techniques. With such animation the user can watch what happens instead of being forced to interpret a radical new image. Furthermore, with these animations the attention of the user is directed to the distortion introduced by the abstraction.
Figure captions are more important for static images resulting from an abstraction, but they are also useful to summarize an abstraction in different levels of detail and focused on different aspects. Furthermore, causalities cannot be expressed by animations, e.g. transparent object due to hidden focused objects. The combination of animation and figure captions is currently being investigated and promises to reduce the complexity of descriptive figure captions. Nevertheless, figure captions remain an efficient means to direct the user's attention to important aspects in the animation. The generation of figure captions for animation is an interesting point for future work.
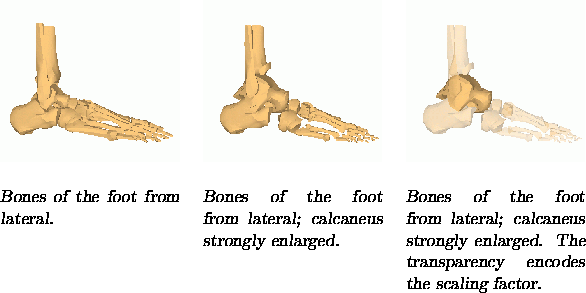
Figure 9: Visualization of the distortion introduced by
abstraction and descriptive figure captions. The upper
illustration shows the bones of a human foot in original
scale. The middle illustration is focused on a bone in the
center using 3D Zoom which causes an enlargement of this
bone, while all other object shrink in order to fit on the
same space. Within the lower illustration the scaling
factor is mapped onto transparency. With kind permission
of Andreas Raab.
Visualization of the distortion introduced by abstraction. The analysis so far shows the importance of describing the distortion introduced by some abstraction techniques. Additional presentation parameters like transparency may be used to visualize the geometric distortion introduced by abstraction methods in the rendered image (see also [4]). Grey-scale values are employed in [4], for example, to communicate the extend to which a fish-eye view differs from the corresponding normal view. As this is just another abstraction, its effect could be described within figure captions.
As mentioned in Section 2, the selective scaling
of objects may lead to a misinterpretation of the resulting image.
The 3D Zoom is a very powerful abstraction technique which introduces
a scaling of all objects within the illustration. In the
middle part of Figure 9, one bone is emphasized using
3D Zoom [22], whereas the upper part of that
illustration illustration which depicts an unscaled rendition of the
model. To emphasize the distortion introduced by the application of
the 3D Zoom, the scaling is mapped on transparency values in the lower
illustration of Figure 9.![]()
Indexing of rendered images with figure captions. As a figure caption summarizes the content of an illustration, they can be used as an index within multimodal information retrieval [29]. Thus, the automatic generation of figure caption for screen-shots of interactively created computer graphics may serve as an automatically created index. As these illustrations are interpreted in the absence of the interactive situation in which they have been generated, they should summarize the interaction applied.
Descriptive figure captions in technical documentation. An interesting area for future work is the application of the ideas developed in this paper to technical documentation. In this area, 3D models resulting from the actual construction process are used to support people who repair and maintain technical devices. We developed a system for the interactive exploration of technical documentation ([9] and [10]) which uses a number of abstraction techniques to emphasize objects. In Figure 10 a combination of line-drawing and shading is used in order to focus the illustration on the motors. As again 3D models are involved, similarities between this area and medical illustrations exist. In particular, viewing directions as well as the visibility of objects are crucial.
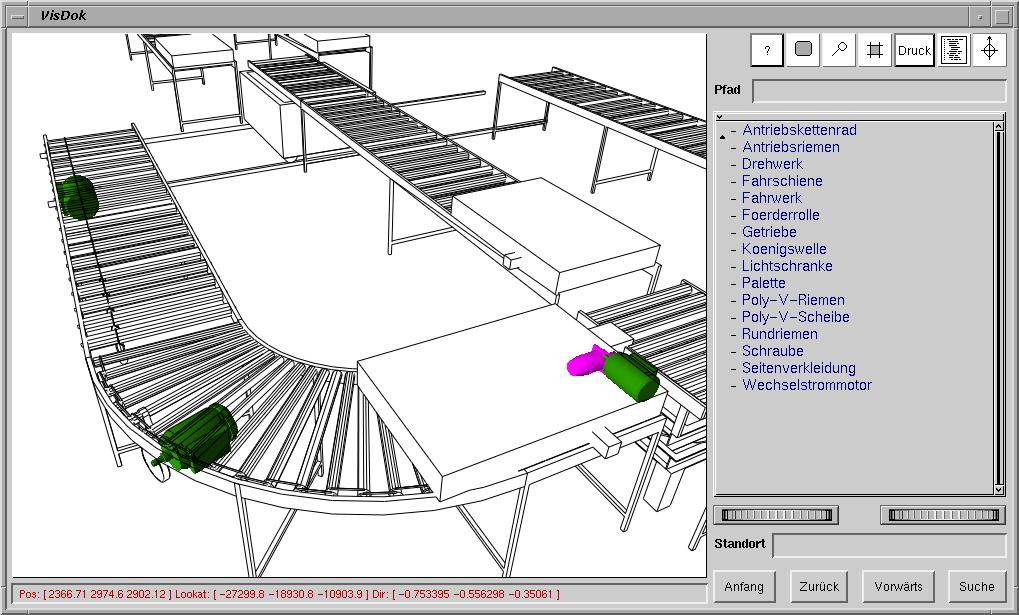
The coding area of a package distribute center with focus on motors.
Figure 10: An illustration of a complex technical device and a
descriptive figure captions in technical documentation.
Empirical evaluation of abstraction techniques. When the application of abstraction techniques are reflected within figure captions it give some hints on their importance. Further work must incorporate an empirical evaluation, in order to derive a fine-grained evaluation of abstraction techniques.
Furthermore, empirical evaluation should analyze the importance of potential structural elements of the macrostructure (recall Section 7.2) in figure caption for different user groups and parameters to which the visual interface may be adopted to.
Refinements of the realization of figure captions. In the current implementation, we employ the template-based approach (recall Section 7.2 and Section 7.3) for the realization of figure captions. As we pointed out in Section 7 this may lead to monotonic text. To overcome this, the number of different templates within a template category could be enlarged. When figure captions in different target languages are required the number of templates increases further, resulting in high maintenance efforts [25].
The combination of template-based and linguistically motivated
generation in the realization of figure captions will be investigated
in the future. In this enhanced framework, text operators as used in
text planning techniques![]() will replace the structural
elements and their specification. These text operators can take the
interaction history into account to avoid redundant information in
captions.
will replace the structural
elements and their specification. These text operators can take the
interaction history into account to avoid redundant information in
captions.
Text-to-speech. In a learning scenario with permanent user interaction, the user will focus on the graphics and thus might not notice the content of figure captions or even dynamic changes within them. In Section 5.1 incremental additions to existing figure captions were proposed to ease the recognition of new parts of the figure caption. But this method does not overcome the conflict of competing content in different output media. Spoken comments, however, can be perceived by the user in parallel. This would require a modification of the realization as to the peculiarities of spoken output. The fixed structure on which both generation methods are based would lead to the constant repetition of large parts of the comments. Furthermore, the problem resulting from redundant information (as mentioned in the last paragraph) would increase. Hence, the spoken comments should mention only system-initiated changes in response to user interaction, while the full content of the figure caption should only be conveyed at user's request.