Figure 1
Responsibility: Vito Pirrelli, Claudia Soria
In fact, such a principled expectation is not borne out entirely in practice. First, there is an issue of frequency and nature of the linguistic phenomena which are likely to appear in dialogue texts. Although it is true that even hesitators like 'ums' and 'ers' occur in fictional dialogue, it can hardly be ignored that interjections and hesitators are vastly more frequent in speech than in writing. As will be argued more extensively in the remainder of this report, frequency and variety make the difference for annotation: if an accidental feature of language becomes systematic, then an annotation scheme has to make provision for it.
Moreover, there is a wide range of phenomena (ranging from anacolutha to disfluencies) which are in fact specific to spoken language only. Again, they will be considered in this context insofar as they raise problems of annotation at the levels of morphosyntax and syntax proper.
Following Leech et al. 1998 (LE-EAGLES-WP4-3.1), it is useful to part the list of linguistic phenomena of specific interest in dealing with dialogue texts into two large and still closely interconnected classes:
The alternative approach (CHRISTINE and UCREL) is to include the disfluent material in the syntactically annotated material.
As a matter of principle as well as of practice, both approaches require preliminary manual annotation of the critical (disfluent) material, but it is clear that while normalization calls for no major adaptation/augmentation of existing annotation software, inclusion of disfluencies during parsing does indeed call for a considerable stretching of common-or-garden notions of phrase structure, or any other suitable syntactic notion for that matter. It remains to be seen whether it is possible to strike a compromise between the requirements of (automatic) parsing on the one hand, and the concern of departing from the attested linguistic evidence available as little as possible. As we will see in some detail later in this report, definition of more than one level of syntactic annotation, ranging from shallow parsing to annotation of grammatical functions such as subject and object, goes some way in providing room for such a compromise.
Although the notion of orthographic word and its associated notions of morphosyntactic word (or syntactic atom) and phonological word (or word stress domain) is in most cases well-established enough not to raise doubts about the orthographic rendering of a sequence of spoken words in an utterance, still there are cases where problems of segmentation may arise. Is a compound such as 'railway station' an orthographic unit as well as a single morphosyntactic and arguably phonological unit? Are expressions such as 'I mean, mind you, good morning, sort of, kind of' to be interpreted and accordingly tagged as one morphosyntactic unit? Although these problems are not confined to dialogue annotation, they get particularly thorny in this context due to i) their interaction with both orthographic transcription and interpretation of word partials and partially intelligible words, and ii) greater density of their occurrence in spoken language. This is particularly clear when things are looked at from the perspective of automatic annotation. For example, if the phenomenon of multi-words is ignored (as indeed it is ignored by some well-known taggers), their high frequency in dialogue is likely to introduce a considerable amount of syntactically non canonical (i.e. non compositional) sequences of tags (as in 'I kind of like it'), with the practical consequence of either introducing noise in the training of a probabilistic tagger, or repeatedly tripping up a probabilistic tagger trained on written texts. In fact, in many cases, the tagging of single constituents of a multi-word unit makes comparatively little sense from a syntactic point of view.
It is clear that, from the perspective of developing an annotation scheme, these issues should be addressed explicitly, with explicit guidelines for manual annotation. Eventually, the extent to which software tools for automatic tagging will be augmented/modified will greatly depend on decisions taken at the level of the annotation scheme.
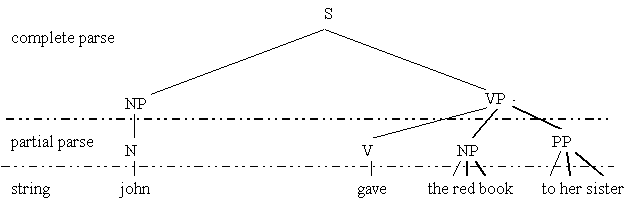
The canonical sentence of written language, as a maximal parsable unit containing at least one finite verb, represents only a kind of ideal syntactic structure when it comes to segmenting real dialogues. In fact, in many cases, utterances typically consist of one word only, often not a verb. If we also consider anacolutha, syntactic incompleteness and other related disfluency phenomena, it becomes immediately apparent that any attempt to construe maximal syntactic projections on the basis of the concatenation of intermediate phrase structures is doomed to failure in many cases. In practice, some tree banks use maximal parse brackets to enclose the whole parsable unit, and make no assumption about its internal structure. This is what the guidelines of the British National Corpus call 'structure minimization principle'. This is certainly preferable to the alternative strategy of editing out major disfluencies, so that parsing is eventually only applied to relatively well-behaved utterances. In the first place, disfluencies, as we saw, are not the only source of difficulties in parsing dialogue sentences. Secondly, it is indeed useful to sketch syntactic (sub)structures even for incompleteness and repair phenomena, as this can represent a valuable source of information for both annotation and software development (as in this case of cross serial correspondences between the reparandum and the alternation in speech repairs, see Heeman and Allen 1997) and psycholinguistic studies. Thirdly, it is difficult to see how the normalization strategy can be applied to some markedly disfluent utterances without imposing an artifact interpretation on the dialogue, unless this sort of utterances are completely expunged from the corpus.
Another viable parsing strategy can be offered as an alternative to both structure minimization and normalization: so-called 'partial parsing'.
In this context, partial or incomplete parsing will be
understood as a form of underspecified parsing whereby a syntactic sketch
is carried out by segmenting a sequence of word forms into nonrecursive
constituents called chunks, as illustrated by the intermediate level of
embedding in the following diagram:
Figure 1
In fact, it is important to bear in mind that the diagram in figure 1 is only illustrative, and should not be interpreted as suggesting that text chunking is simply an intermediate stage in the process of generating a full constituency-based parse of a sentence. Later in this report, we will consider in more detail a particular chunking scheme which appears to be amenable to a dependency-based syntactic representation. Be that as it may, what all chunking schemes seem to have in common is the local character of their proposed analyses, with particular emphasis on the fact that the syntactic relations holding among chunks are not necessarily spelled out.
This aspect is particularly relevant to dialogue annotation, for example in connection with the analysis of phrase partials or syntactic blendings. Since partial parsing does not enforce any overall consistency checking of levels of structural embedding higher than chunks (that is, as to the way chunks are eventually related to the topmost nodes in a sentential tree), a shallow parser does not balk at the occurrence of phrase partials, nor does it attempt to keep an anacoluthon in line with the overall syntactic construction. In this respect, shallow parsing yields an output which is the mirror image of the representation required by the 'structure minimization principle': instead of providing the most comprehensive structure compatible with the data (with no indication of its internal substructures), shallow parsing outputs a list of unrelated minimum syntactic structures which are compatible with input data. This strategy can provide useful information also about portions of the original dialogue which are eventually expunged from a normalized transcription of the dialogue in question (for example, in the case of retraced-and-repaired sentences).
As we will see in more detail later in this report, chunking is usually taken to be only the first stage in the process of augmenting input data with syntactic annotation. In the specific case of dialogue annotation, the transition from shallow to complete parse presupposes prior identification of disfluencies (either manual or automatic), for the latter to be conveniently pruned out from the final representation of the syntactic structure of an utterance, be that expressed in terms of a sentential phrase marker (a tree), or a dependency chain, or otherwise. It is our contention that this process of step-wise abstraction from concrete input data is inevitable and inherent in the idea of augmenting input data with richer and richer levels of annotation. The step-wise approach to syntactic analysis suggested here has the nonnegligible advantage of providing graded levels of abstraction, from fairly local analyses to overall ones, so that even extra-grammatical phenomena such as disfluencies are annotated syntactically at some (low) level, to eventually be ignored at higher levels.
For a detailed description of schemes see Appendix D.
Unlike inflection, derivation lends itself more naturally to being dealt with in terms of morpheme splitting. "Morpheme segmentation", either immediate (e.g. signalling the most external affix only, as in "derivation-al"), or complete (as in "deriv-ation-al") or hierarchical (as in "(((deriv) ation) al)") is provided, for example, in the CELEX electronic lexica (Burnage 90.). Yet, this type of representation is, in general, not able to account for, e.g., stem allomorphy, although this is admittedly far less frequent than in inflectional morphology. For lack of better encoding practices, immediate morpheme segmentation (flat) could be proposed as a reasonable minimal annotation strategy for encoding derivational morphemes.
Although compounding represents another critical area for both theoretical and computational Morphology, annotation of compounds (as opposed to their identification or their interpretation) can be a relatively trivial issue if it is limited to signalling the membership of a sequence of word forms (such as copy and editor in "copy editor") to a morphosyntactically unique word. This problem is common to annotation of other types of multi word units.
We contend that these two levels of syntactic annotation, augmented with their linking to a common level of (edited) orthographic transcription of the acoustic signal, can be instrumental in getting around the stricture of the two radically different approaches to syntactic annotation of dialogue material proposed so far: namely i) normalization of orthographic transcription on the one hand, and ii) stretching of the annotation scheme to deal with unrestricted text on the other hand.
The problem with the alternative between i) and ii) lies in the fact that normalization gets rid of precious information, by disregarding material such as repaired speech which it would be useful to annotate at the syntactic level anyway (as illustrated by work of Core and Schubert, 1997). On the other hand, unedited spoken material is, in some extreme cases (e.g. child language), so difficult to deal with through any set of syntactic rules, than any notion of stretching the syntactic annotation here would inevitably lead to an uninformative output.
The compromise that we intend to suggest here is based on the idea of gradual abstraction from the raw, unedited orthographic transcription of the acoustic signal. Different levels of syntactic annotation can be developed which convey syntactic information at progressively higher levels of abstraction. Accordingly, different phenomena specific of speech are dealt differently depending on the level of syntactic annotation one is considering. For example, repaired speech should, in our view of things, annotated at the chunk level (see relevant examples provided in the overview). Among other things, this is also important for their identification, owing to the parallel structure usually exhibited by a reparandum and its alteration. On the other hand, it is generally meaningless to include the reparandum in a functional annotation, where only target or intended units (as opposed to actually uttered ones) are eventually taken into account. A possible exception to this general principle is represented by the case when a pronoun in the alteration refers back to a noun phrase in the reparandum, as in:
Take the oranges to Elmira, uh, I mean, take them to Corning
Here, it can be argued that functional annotation of the alteration requires intended information provided in the reparandum ("the oranges"). In fact, it is dubious that functional annotation should include disambiguation of the referential content of pronouns. Be that as it may, this case calls for exceptional reference to edited (repaired) material, and gives further support to an annotation practice whereby edited material is simply conveniently marked, but not expunged, so that it can be recovered if the need arises.
It remains to be seen how the two (or possibly more) levels of syntactic annotation should mutually be related. In short, two solutions can be envisaged: a) direct linking of the required levels, b) indirect linking through reference to a common level of edited orthographic transcription. Both solutions have pros and cons. On the one hand, it seems useful that functional annotation be built on a chunked text. On the other hand, the level of chunking is still too raw to provide an appropriate anchor for annotation at the functional level (for example, given a pronoun uttered thrice, which one of these tokens should be actually linked to the level of functional annotation? See discussion in the relevant section of the overview). Editing is felt useful in this context in order to i) allow a functional parser to disregard irrelevant phenomena (such as repetitions and repairs), ii) provide the target anchor to be referred to at the level of functional annotation.
Finally, it should be noted that the standard developed within SPARKLE offers the additional advantage of leaving room for underspecification depending on the specific requirements of the language being annotated. This is made possible thanks to the specification of a hierarchical typology of grammatical functions (see relevant section in the overview part), which has been designed so as to meet the grammatical requirements of English, French, German and Italian. We are aware of no other comparable effort along the same lines.
As to the treatment of phrase partials, CHILDES seems to provide a useful set of markers signalling the point where the expected phrase appears to be interrupted, and, possibly, the point where it is resumed, either by the same speaker or through completion by another interlocutor. The analogous scheme provided in Switchboard is, for what can be judged from the annotation manual, needlessly overspecific and of difficult application. Moreover, the strict assumption, made in Switchboard, that a phrase partial can only be completed by the same speaker who uttered the partial in the first place, strikes us as too abstract and not sufficiently motivated.