It seems to be more plausible to test the ambiguity of a partial string
with respect to already produced partial strings. Based on this idea the
notation of context is considered as follows:
The context of a partial string ![]() with constituent A is the
string
with constituent A is the
string ![]() of the adjacent constituent B of A. Parsing is then performed
on the ``extended'' string
of the adjacent constituent B of A. Parsing is then performed
on the ``extended'' string ![]() , to test whether this string leads
to some ambiguity. If the ``extended string'' is either not parse-able or
is not ambiguous we conclude that the newly produced string
, to test whether this string leads
to some ambiguity. If the ``extended string'' is either not parse-able or
is not ambiguous we conclude that the newly produced string ![]() does
not force ambiguities in the current state of computation of generating the
final string.
does
not force ambiguities in the current state of computation of generating the
final string.
For example suppose that an
utterance with meaning `Remove the folder by means of the system tools.' has
to be produced.
Furthermore, suppose that the partial string `Remove the folder' has
been generated using a rule `vp ![]() v, np, pp'. Now, the result of
generating the pp is `with the system tools'. In order to check whether
this string is ambiguous `the folder' is used as context and the string
`the folder with the systems tools' is parsed. This string is parse-able
if a rule e.g., `np
v, np, pp'. Now, the result of
generating the pp is `with the system tools'. In order to check whether
this string is ambiguous `the folder' is used as context and the string
`the folder with the systems tools' is parsed. This string is parse-able
if a rule e.g., `np ![]() np, pp' exists. If it is parse-able then a
source of ambiguity has been found, so that pp should be revised. If
revision is not possible, then revision of the previous chosen vp should take
place. However, if the rule `vp
np, pp' exists. If it is parse-able then a
source of ambiguity has been found, so that pp should be revised. If
revision is not possible, then revision of the previous chosen vp should take
place. However, if the rule `vp ![]() v, pp, np' had been chosen, and
the currently produced string is ``the folder'', then the extended string to
parse would be ``with the system tools the folder''. In this case, however,
the string would not be parse-able. For the monitoring strategy this means,
that at this point of computation, no statement of a possible ambiguity
can be made, so the revision should not take place. In other words, the newly
produced string ``the folder'' does not cause a relevant ambiguity in the
current domain of locality spanned by the vp rule.
v, pp, np' had been chosen, and
the currently produced string is ``the folder'', then the extended string to
parse would be ``with the system tools the folder''. In this case, however,
the string would not be parse-able. For the monitoring strategy this means,
that at this point of computation, no statement of a possible ambiguity
can be made, so the revision should not take place. In other words, the newly
produced string ``the folder'' does not cause a relevant ambiguity in the
current domain of locality spanned by the vp rule.
The proposed approach realizes a kind of look-back strategy, in the sense, that the monitor look backs to already produced substrings, in order to test whether a new string together with previous produced substrings causes ambiguity. For the method described so far, we actually have made a look-back of one adjacent constituent. In principle, however, it is possibly also to take into account the adjacent element of an adjacent element, leading to a look-back(n) strategy. The degree of look-back used, directly influences the degree of ambiguity we are going to consider. For example suppose we have the following grammar (s, np, vp are non-terminals, the other symbols are terminal elements):
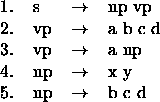
Assume that we have first chosen the vp rule 2., and the newly generated element is d (we assume a left-to-right scheduling). If we are following a look-back(1) strategy, then we have to parse the string `cd'. This string, however, is not parse-able, so we do not try to revise it at that point. However, if we would use look-back(2), the string to parse would be `bcd'. This string is parse-able, so there is the possibility of an ambiguity.
We are now going to describe how the look-back strategy informally described above can be integrated into the uniform algorithm developed in chapter 4 in order to perform the desired incremental monitoring strategy. Basically, we have to discuss the following questions:
The first question is concerned with the problem of determining context. This implies that we have to consider the possible different granulations the shape a context can have. For example, does it make sense to consider only one word as context or should it be better the string of complex constituents. This question will be considered after having introduced how revision should take place, because activation of revision is triggered after having determined a context, but it is possible to discuss revision by just assuming that context has already been determined.
Thus, the first question we want to consider, is the question how revision is realized within the uniform algorithm.