The basic idea is to split the generated items into equivalence classes and to connect these classes, so that each item can directly be restricted to those items that belong to a particular equivalence class. We will call each equivalence class an item set. The whole state set then consists of a set of item sets, which we will call a chart. We will use the current value of the essential feature of some goal G (abbreviated as G) as index for an item set.
We then require that for each item L in an item set I with index Idx, that L must be the same as Idx. However, we have to distinguish between passive and active items. We require that for passive items, the essential feature's value is determined from the feature structure of the head element. Clearly this is the only possibility, since passive items have an empty body. For active items, however, we require that the essential feature's value is determined by the selected element.
More formally, we can define an item set I as a tuple AL,PL,Idx, where PL is a finite set of passive items and AL a finite set of active items such that:
![]()
![]()
Thus all items in one item set share one common property, namely that they are compatible with respect to the value of the essential feature of one of their literals, which is the head in the case of an unit lemma, and the selected element in the case of an non-unit lemma.
In this sense, an item set can be viewed as a kind of meeting place of active and passive items, such that an active item looks for some passive item to resolve with, and vice versa, that a passive item looks for an active item which it can resolve. However, both are identical with respect to the value of their essential feature. If the result of the reduction operation is a new item, this item will eventually be placed in another item set.
If we start with a start item representing the goal to prove, the start item will be inserted into an item set with an index determined from the value of the essential feature of the query. We will call the item set built from the start item the initial item set. We end successfully, if the initial item set entails the reduced goal.
The inference rules will be responsible for creating and maintaining item sets. In order to reuse items that have been predicted in one item set for items in other item sets, we have to link the serval item sets. We will basically use the same mechanism as Earley's algorithm or from Chart parsing, i.e., for each item we keep a backward pointer. The meaning of the backward pointer is the index of that item set from which the initial prediction of some goal was made. If an active item can be reduced, the reduced item inherits the backward pointer from the active item. Thus, an ancestor of an initially predicted item will have the same backward pointer. However, since the indices of item sets are determined on the basis of the value of the essential feature, and the essential feature is the one that carries either a string or semantic expression, the structure of the linked item sets represents the relationship between parts of the input in the way the grammar has decomposed the input.
Before we can clarify this behaviour, we first have to adopt the item structure to the requested information. We add two new slots to an item. A new slot FROM which holds the backward pointer to the item set the item has been predicted from. The slot IN holds the index of the item set of which the item is a member. The general form of an item is as follows:
![]()
Thus each lemma knows from which item set it has been predicted and of which item set it is a member. The values of these slots for a particular item will be accessed by functions having the same name as the slot names. Thus IN(Item) denotes the item set Item is a member of and FROM(Item) denotes the backward pointer.
For active items, the value of the IN slot is just the value of the essential feature of the selected element. If we denote this as ea(i), the general structure of active items is
![]()
where the backward pointer ea(k) means that this active item has been predicted from some active item whose selected element has value ea(k). The general structure of passive items is
![]()
Since the value of the essential feature of the head of
the active clause must not change, when reducing its body, ea(k) is
just the value ea(head(al)) or ea(head(pl)) in the case of passive
items.![]()
But then, passive items in some item set correspond to some grammatically well-formed structure that has been found for ea(k) which corresponds to a part of the whole input. However, we also know that there must be some active item with which the passive item can resolve, since passive items are the result of reduction of some active items.
By definition, these active items and the passive items belong to the same item set. Since active items must originate from top-down prediction of the start item, this means that passive items correspond to valid partial grammatical structure of the input in question. However, this is only true, if the input may not be changed (by deleting parts or by adding parts). But this is exactly what is required by the coherence and completeness condition of the -proof problem. We will next describe the inference algorithm on basis of this notation, before it is specified in terms of our pseudo programming language.
The indices of the start item will be determined from the value of the essential feature of a query. This value will serve as the IN and FROM pointer of the start item. Let q be the query and Ea, the value of its essential feature. Then the start item is as follows (because q is the only element of the body its index is 0):
![]()
Thus, if we start with a string or semantic expression, and if we can reduce the goal, the initial item set contains an answer of the goal that characterizes the input in question as a valid sign of the language.
The adoption of the four inference rules can be done very similarly. All of them generate either active or passive items depending on the form of the new lemma of the generated item. If the generated item is active, this active item will be added to the item set, whose index is determined on the basis of the selected element of the new item. If such an item set does not exist, it will be created. If the generated item is passive, we add it to the item set which is indicated by the backward pointer of the active item it was generated from. Note that such item set must exist, because otherwise the passive item would not exist.
In all of the inference rules at least active items are involved. They only differ with respect to the second structure involved. For the predictor and scanner this will be the grammar and lexicon. Passive items are involved for passive completion and active completion. Using the notation above, we can describe the inference rules as follows:
Prediction will predict new instantiations of grammar rules on the basis of the selected element of an active item of form
![]()
If R is a non-unit unified grammar rule of form ![]() with selected element
with selected element ![]() , then generate item
, then generate item
![]()
otherwise (i.e., R is a unit rule) generate item
![]()
This means that an instantiated empty production will always be placed into the same item set from which prediction took place. Note that the predictor basically links predicted items on the basis of the value of the essential feature of their selected elements.
Scanning will reduce an active item on the basis of unified lexical material. If the selected element of an active item of form
![]()
can be unified with some lexical entry L, and if the reduced lemma rl (i.e., the unified clause minus its selected element) is non-unit, then generate item
![]()
otherwise, generate item
![]()
Two points are important to note here. First, the scanner reduces an active item on the basis of lexical material, which corresponds to some part of the input string or semantics. This means, that for the reduced lemma, this part of the input has actually been consumed. Second, the new generated item inherits the backward pointer of the active item. In principle this means that the scanner defines a lower bound for the chain of predicted items that lead to a unified lexical entry. If the new generated item is an active one, then the selected element initializes a new prediction chain.
Passive completion operates on a passive item and searches for active items, which are in the same item set as the passive one. Thus if the passive item is of form
![]()
and if there is a unify-able active item of form
![]()
and if the reduced lemma rl is active, then generate item
![]()
otherwise (i.e., rl is passive) generate item
![]()
Active completion performs basically the same task with the only difference that it operates on an active item and searches for passive items. Thus if the active item is of form
![]()
and if there is a unify-able passive item of form
![]()
then generate either
![]()
or
![]()
Note that both completion rules can call each other indirectly via ADD-ITEM depending on the form of the generated item.
In summary, the inference rules work together in such a way that the predictor establishes a prediction chain on the basis of the decomposed input, where the completion rules (including the scanner) basically stop a prediction chain, by eventually initializing a new local prediction chain. The next figure 4.12 serves as an illustration of this behaviour.
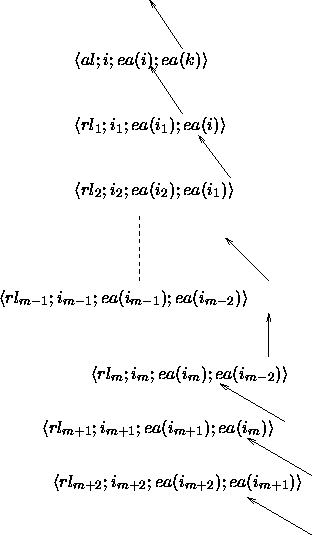
Figure 4.12: The relationship of generated items of the different inference rules.
However, in each case only those items are considered whose essential feature have the same value. Thus each inference rule is only applied on a small subset of items.