In principle the same properties as those already discussed for the
monitored generator are valid. This means, that only unambiguous paraphrases
are generated. Therefore it is guaranteed that the same paraphrase is not
produced for different interpretations.
This is important because it could be the case that a paraphrase, say S ![]() is also ambiguous such that it has the same interpretations as S. Therefore
it could happen that the same utterance S
is also ambiguous such that it has the same interpretations as S. Therefore
it could happen that the same utterance S ![]() is generated as a paraphrase
for both LF
is generated as a paraphrase
for both LF ![]() and LF
and LF ![]() . For example in German the following sentence:
. For example in German the following sentence:
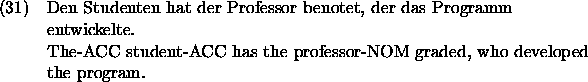
is ambiguous because it is not clear who developed the program. If a paraphrase is to be generated, which expresses that the student developed the program, then this can be done by means of the utterance:
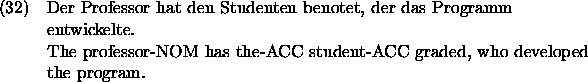
But this utterance has still the same ambiguity. This means, that one has to check also the ambiguity of the paraphrase. An unambiguous solution for the example is, e.g., the utterance:

The advantage of our approach is that only one paraphrase for each interpretation is produced and that the source of the ambiguity is used directly. Therefore, the generation of irrelevant paraphrases is avoided.
Furthermore, we do not need special predefined `ambiguity specialists', as proposed by MeteerShaked:88, but rather use the parser to detect possible ambiguities. Hence our approach is much more independent of the underlying grammar.