=4in
|
Susan W. McRoy (mcroy@uwm.edu) and Syed S. Ali (syali@uwm.edu)
University of Wisconsin-Milwaukee
Milwaukee, WI 53201
Our theory provides a specification and representation of the linguistic, intentional, and social information that influence how people understand and respond in an ongoing dialog and an architecture for combining this information. We represent knowledge uniformly in a single, declarative, logical language where the interpretation and performance of communicative acts in dialog occurs as a result of reasoning.
We are investigating computational models of dialog that can support robust, effective communication between people and computer systems [McRoy et al.1997,McRoy1995,McRoy1998,McRoy and Hirst1993,McRoy et al.1998a,McRoy et al.1998b,Ali et al.1999a,Restificar et al.1999a,Restificar et al.1999b]. Developing such methods requires:
The general model of processing for our work is one of an Intelligent Dialog System [Bordegoni et al.1997]. Intelligent Dialog Systems (IDS) are concerned with the effective management of an incremental, mixed-initiative interaction between the user and the system. This approach is in contrast with a presentation system, where the system's outputs are pre-planned (e.g. driven by a fixed plan or grammar) and not adapted to the user's apparent understanding or lack thereof. In an IDS, content to be presented, as well as the system's model of the user, change dynamically during an interaction.
Reasoning about dialog, such as to determine what a user's actions mean in the context of the dialog, whether a user's actions indicate understanding and agreement, and how to respond to a user's action, requires representing and combining many sources of knowledge. To support natural communication (which may contain fragments, anaphora, or follow-up questions), as well as to reason about the effectiveness of the interaction, a dialog system must represent both sides of the interaction; it must also combine linguistic, social, and intentional knowledge that underlies communicative actions [Grosz and Sidner1986,Lambert and Carberry1991,Moore and Paris1993,McRoy and Hirst1995]. To adapt to a user's interests and level of understanding (e.g. by modifying the questions that it asks or by customizing the responses that it provides), a dialog system must represent information about the user and the state of the ongoing task.
The architecture that we have been developing for building Intelligent Dialog Systems includes computational methods for the following:
In what follows, we present an architecture and computational theory that addresses these issues. We present a detailed example of the representations and processing require to answer a question. We will then describe some of the components of our work and how they make use of the uniform, declarative representation of dialog.
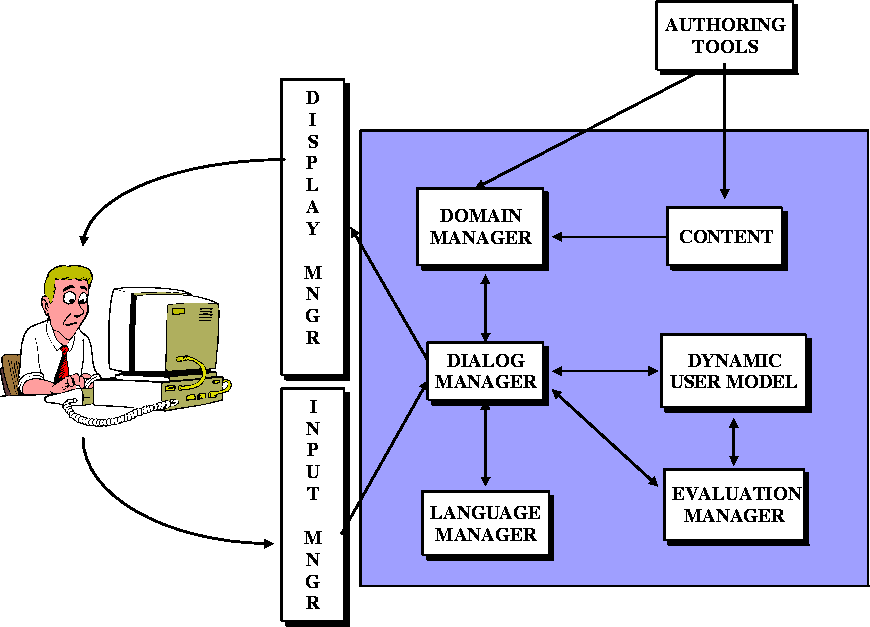
Our architecture for Intelligent Dialog Systems is shown in Figure 1. The INPUT MANAGER and DISPLAY MANAGER deal with input and output, respectively. The input modalities will include typed text, spoken text, mouse clicks, and drawing. The output modalities will include text, graphics, speech and video. The DIALOG MANAGER is the component through which all input and output passes. This is important because the system must have a record of everything that occurred (both user and system-initiated). If the user chooses to input language, the LANGUAGE MANAGER is handed the text to parse and build the appropriate representation which is then interpreted by the dialog manager. The DOMAIN MANAGER component will be comprised of general rules of the task as well as specific information associated with how the CONTENT is to be presented. The content will be generated, prior to system use, by the use of AUTHORING TOOLS that allow the rapid development of the content. Based on the ongoing interaction, as well as information provided by the user, USER BACKGROUND & PREFERENCES are tracked. The status of the interaction is evaluated incrementally by the EVALUATION MANAGER, which affects the ongoing dialog and user model. We will present some of these components in more detail in Sections 4 and 5.
This architecture builds on our prior work, where the user is on a ``thin'' client personal computer interacting with a server that contains all the components described [McRoy et al.1997]. Most components of this architecture are general purpose; to retarget the system for a new domain, one would need to respecify only the domain and content.
All components within the large box on the right share a common representation language and a common inference and acting system.
Actions by the user are interpreted as communicative acts by considering what was observed and how it fits with the system's prior goals and expectations. First, a parser with a broad coverage grammar builds a mixed-depth representation of the user's actions.2 This representation includes a syntactic analysis and a partial semantic analysis. Mixed-depth representations are constructed incrementally and opportunistically. They are used to address the ambiguity that occurs in utterances, without sacrificing generality. Encoding decisions that require reasoning about the domain or about the discourse context are left to subsequent processing.
Second, the dialog manager uses domain knowledge to map linguistic elements onto domain elements and to refine some semantic structures. This level of processing includes the interpretation of noun phrases, the resolution of anaphora, and the interpretation of sentences. For example, the mixed-depth representation leaves the possessive relationship uninterpreted; at this stage, domain information is used to identify the underlying conceptual relationship (i.e. ownership, part-whole, kinship, or object-property), as in the following:
The man's hat (ownership); the man's arm (part-whole); the man's son (kinship); the man's age (object-property).
Next, the dialog manager identifies higher-level dialog exchange structures and decides whether the new interpretation confirms its understanding of prior interaction. Exchange structures are pairs of utterances (not necessarily adjacent, because a subdialog may intervene) such as question-answer or inform-acknowledge. The interpretation of an exchange indicates how the exchange fits with previous ones, such as whether it manifests understanding, misunderstanding, agreement, or disagreement.
Finally, the assertion of an interpretation of an utterance triggers the appropriate actions (e.g. a question will normally trigger an action to compute the answer) to provide a response. In Section 3.2, we will illustrate our approach by working through the answer to a question: What is Mary's age?.
The inference and acting system provides services used for interpreting the user's actions and for constructing a response:
The particular knowledge representation system that is used is SNePS [Shapiro and Rapaport1992]. SNePS provides facilities for building and finding nodes, as well as for (first- and second-order) reasoning, truth-maintenance, planning/acting, and knowledge partitioning (for user- and system-models). Our theory is knowledge-intensive, knowledge partitioning allows tractable inference in real-time.
|
Case frames are used to represent propositions. Case frames are conventionally agreed upon sets of arcs emanating from a node. For example, to express the proposition that A isa B, we use the MEMBER-CLASS case frame, which is a node with a MEMBER arc and a CLASS arc. Figure 2 shows the construction and representation of Tweety is a bird as node M1!. An extensive collection of standard case frames is provided in [Shapiro et al.1994] and additional case frames can be defined as needed. We use many standard case frames as well as several new ones.
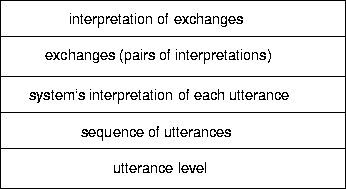
The utterance level is a (mixed-depth) representation of what the user typed or selected with a mouse, as produced by the parser. The second level corresponds to the sequence of utterances, which enables the system to reason about temporal ordering constraints. (This level is comparable to the linguistic structure in the tripartite model of [Grosz and Sidner1986]). The third level comprises the system's interpretation of each utterance. Each utterance event (from level 1) will have an associated system interpretation, which corresponds to a communicative act (such as question or command) which may reference entities from the underlying task. The fourth and fifth levels of the discourse model are exchanges and interpretations of exchanges, respectively. These levels represent a key difference between our work and previous approaches. These structures are determined on the basis of a number of domain-independent schemata which are represented declaratively in a logical language. The starting point for these schemata was sociolinguistic accounts of dialog [Schegloff1992,Clark and Schaefer1989] and Grice's [Grice1975] notion of reflexive intentions. Most AI approaches to dialog are based on Searle's [Searle1969,Searle1979] account of speech acts and STRIPS [Fikes and Nilsson1971,Sacerdoti1977] style plan operators of traditional AI. Our approach is more flexible and can better adapt to failed expectations (such as in misunderstanding or argumentation).
We illustrate some (but not all) of the levels of our dialog model for the dialog below:
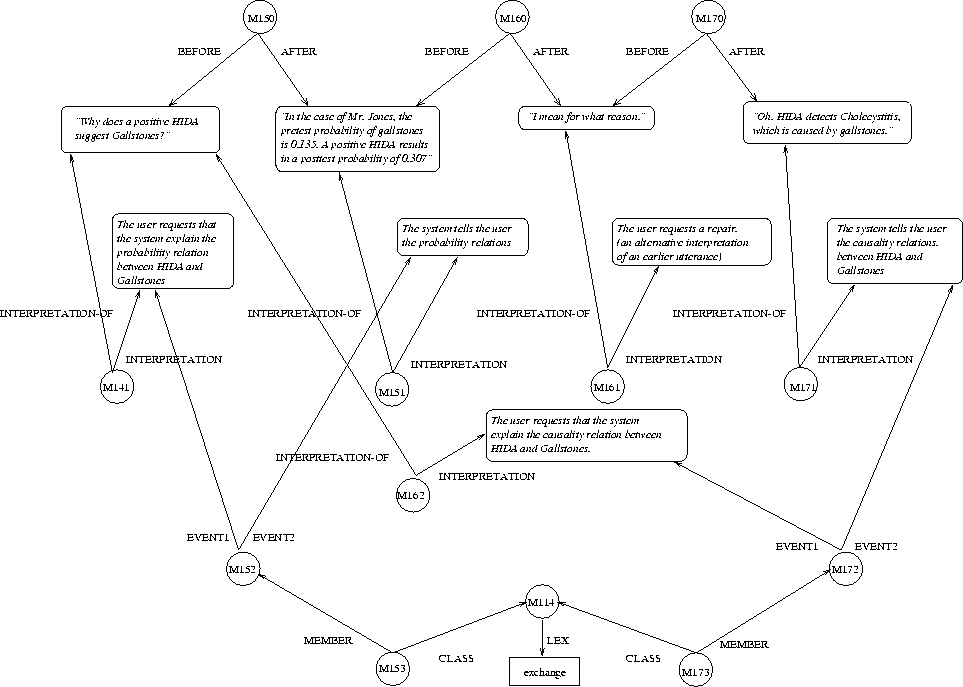
Figure 4 illustrates the utterance sequence, interpretation, and exchange levels of representation that would result after this conversation. 3Starting from the top of the figure, we see the following:
User: Why does a positive HIDA suggest gallstones? 1 B2 In the case of Mr Jones, the pretest probability of gallstones is 0.135. A positive HIDA test results in a post-test probability of 0.307. 2 User: I mean for what reason. 3 B2: Oh. HIDA detects cholecystitis, which is caused by gallstones. 4
=6in
|
The exchange structure is significant because, the system will step back through this structure if it needs to reason about alternative interpretations. The exchange structure indicates how each speaker displayed their understanding of the other's previous utterances. (The utterance sequence will not always provide this information because exchanges can be nested inside each other, e.g. to ask a clarifying question.)
The interpretation of M161 is special, because it neither begins a new exchange nor completes an open one. (This would be determined by its linguistic form and by the expectations created by the previous interaction.) When the system fails to find a domain plan (e.g. a request to display part of the network) or a discourse plan (e.g. a request to clarify a previous utterance or an answer to a question from the system), then it considers evidence of failure. In this case, the surface form of the utterance suggests looking back in the conversation to consider an alternative domain plan. Finding an utterance that admits an alternative interpretation-corresponding to an alternative domain plan--a new interpretation (M162) is constructed, which results in a repair action by the system to accept it. (If there had been no alternative domain plan, then the system would not be able to form any interpretation of utterance 3--a case of non-understanding--and would subsequently ask the user to provide more information about the problem.)
The result of dialog processing is thus a detailed network of propositions that indicates the content of the utterances produced by the system or the user, their role in the interaction, and the system's belief about what has been understood. If necessary, the system will be able to explain why it produced the utterances that it did and recover from situations where communication has failed.
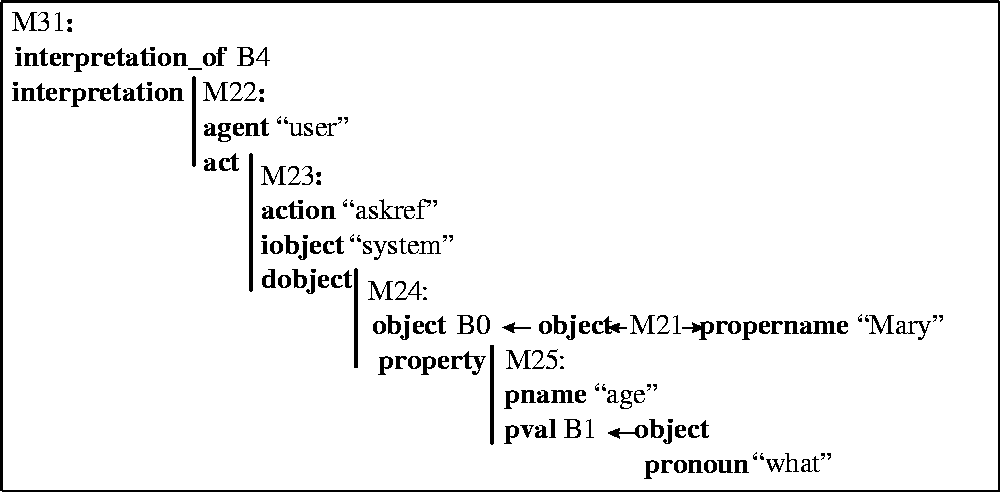
To illustrate, we will now consider the underlying representations that are used when processing the question: What is Mary's age?. The steps that occur in answering this question are:
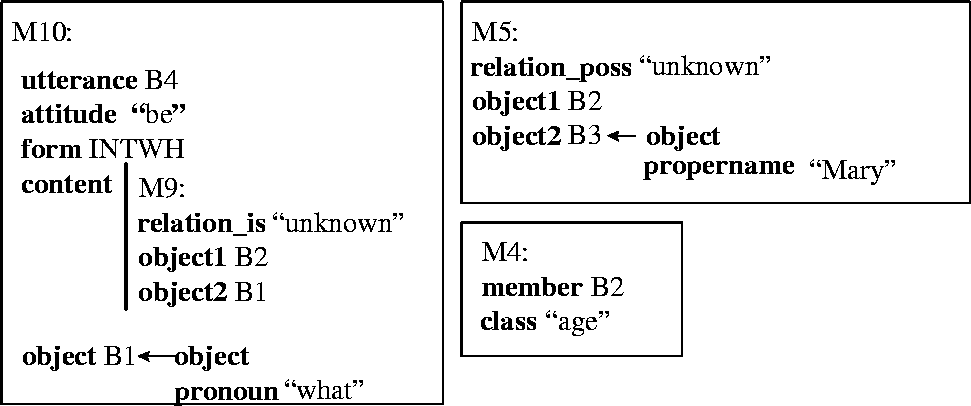
As mentioned above, the question is parsed by a broad-coverage grammar which builds the utterance-level (mixed-depth) representation(s) as shown in Figure 5. For clarity, the semantic networks are shown as simplified feature structures. Propositions are labeled as Mj and (potential) discourse entities are labeled as Bk. In Figure 5, three propositions are produced from the initial parse of the question. Proposition M10 represents the fact that there was an utterance whose label is B4, whose form and attitude was interrogative copula, and whose content (M9)is some unknown is relation between B2 and B1. B1 corresponds to the pronoun what and B2 to age. Proposition M4 states that B2 is a member of the class of age. Finally, proposition M5 represents the fact that there is an unknown possessive relationship between B2 (an age) and B3 (an entity whose proper name is Mary).
As can be seen from Figure 5, the utterance-level propositions produced by the parser are the weakest possible interpretations of the utterance. Any question of this form would parse into similar utterance-level propositions; the subsequent interpretation(s) would vary.
In the next step of interpretation, M5 is further interpreted as specifying an attribute (B2, i.e. age) of an object (B3, i.e. Mary). This is a domain-specific interpretation and is deduced by an interpretation rule (not shown here for space reasons). The rule encodes that age is an attribute of an entity (and is not, for example, an ownership relation as in Mary's dog).
=0.5
|
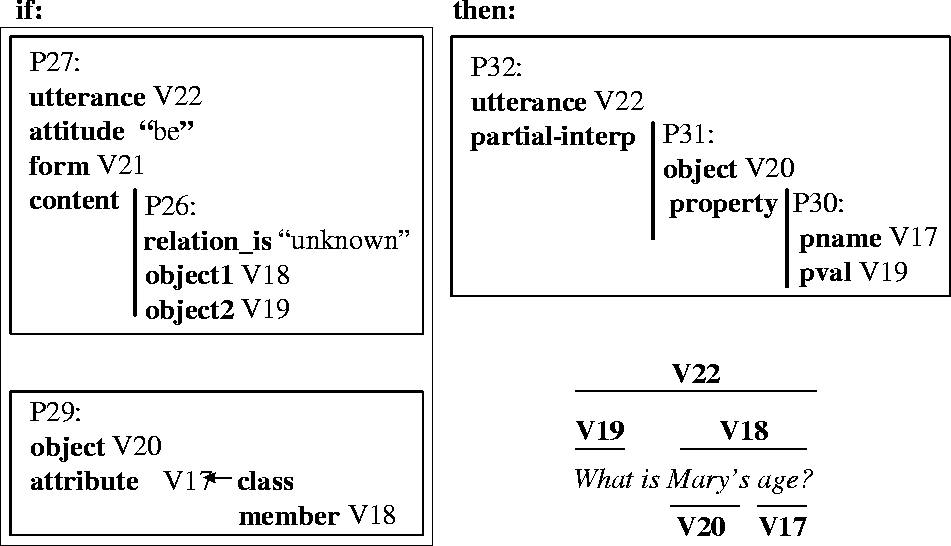
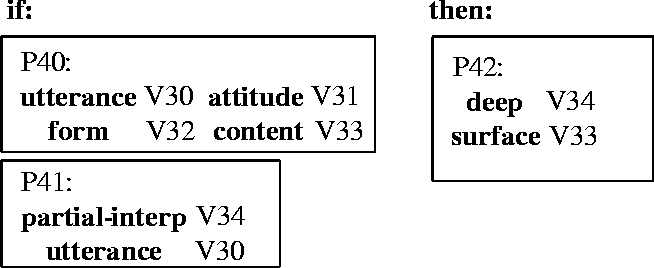
Figure 6 shows the interpretation rule used to deduce a partial interpretation of the utterance B4. A partial interpretation of an utterance is a semantic interpretation of the content of the utterance, apart from its communicative (pragmatic) force. This relationship will also be represented explicitly as a deep-surface relationship, which is derived using the rule shown in Figure 7. 4In addition, a separate rule (not shown) will be used to establish an equivalence relationship between B3 (the Mary mentioned in the utterance) and B0 (the Mary known to the system). 5As a result of the rule in Figure 6, the semantic content of the utterance is interpreted as an object-property relationship (pragmatic processing, discussed in the next subsection, will determine that the force is as a particular subclass of question askref).
In a rule such as in Figures 6 and 7, variables are labeled as Vn and, for clarity, the bindings of the variables of the rules are shown relative to the original question in the lower right corner. The if part of the rule in Figure 6, has two antecedents: (1) P27, requires that there be an copula utterance whose content is an unknown is relation between an entity (V19 i.e. What) and another entity (V18), (2) P29, requires that the latter entity (V18 i.e. age) is an attribute of another entity (V20 i.e. Mary). The consequent of this rule P32 stipulates that, should the two antecedents hold, then a partial interpretation of the utterance is that V20 (i.e. Mary) has a property whose name is V17 (i.e. age) and whose value is V19 (i.e. what). The rule of Figure 6 allows the interpretation of the mixed-depth representations of Figure 5 as a proposition, which expressed in a logical formula, is has-property(Mary, age, what)
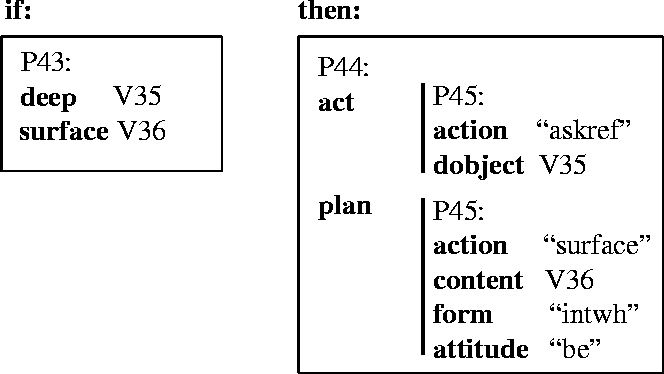
The rule in Figure 8 specifies the relationship between an utterance and the way it may be realized as an utterance. In this case, whenever there is a deep-surface relationship between two propositions V35 and V36, that is, V36 is a representation of how the user might express a proposition and V35 is a representation of how the system represents the concept in its model of the domain, then an agent (either the system or the user) may perform an askref 6 by performing the (linguistic) action called ``surface'' to output the content V36 with a surface syntax of ``intwh'' and attitude ``be''. We call this type of rule a ``text planning rule'' because it may be used by the system either to interpret an utterance by the user or to generate an utterance by the system.
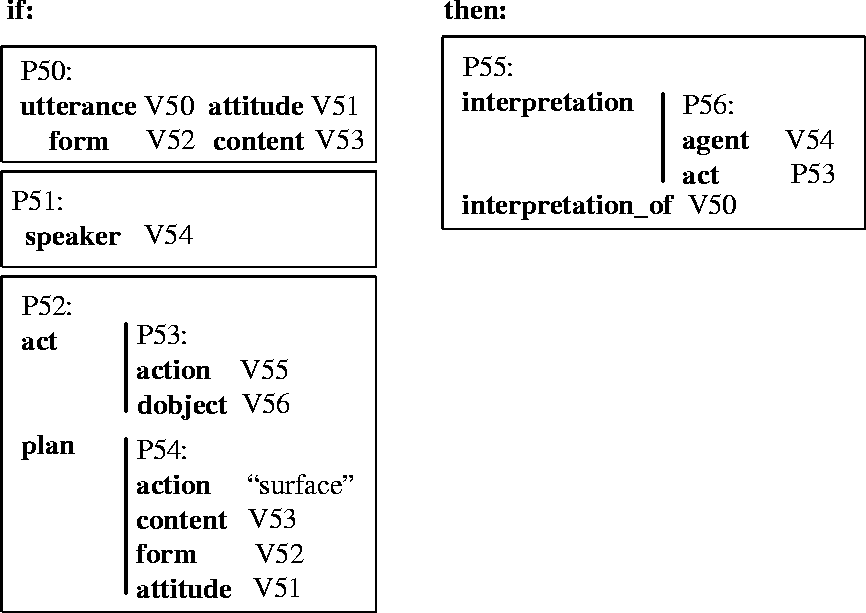
Figure 9 is a rule that specifies a possible interpretation of an utterance. It says that if a speaker makes an utterance, and that utterance is part of a plan that accomplishes an action, then an interpretation of the utterance is that the speaker is performing the action. This rule relies on the results of the text planning rule mentioned above, where P52 is matched against a text plan whose act is the following:
(M23 (ACTION "askref")
(DOBJECT (M24 (OBJECT B0)
(PROPERTY (M25 (PNAME "AGE")
(PVAL B1))))))
and P50 is matched against the output of the parser with
form = intwh, attitude = be, and
content = (M9 (RELATION_IS "unknown")
(OBJECT1 B2)
(OBJECT2 B1))
The final interpretation of the original utterance B4 is shown in
Figure 10.
M22 is the (level 3) interpretation, namely that the user is performing
an askref on what is Mary's age (M24) and the system.
More concisely, the system has interpreted the original utterance
what is Mary's age as the user asking the system: what is Mary's age?.
At this point our discussion of interpretation is complete (we will not consider, here, the possibility of misunderstandings or arguments and hence can safely ignore the construction of the fourth and fifth levels of the discourse model). Next, we will consider response generation, as it illustrates the link between inference and action in the underlying knowledge base.
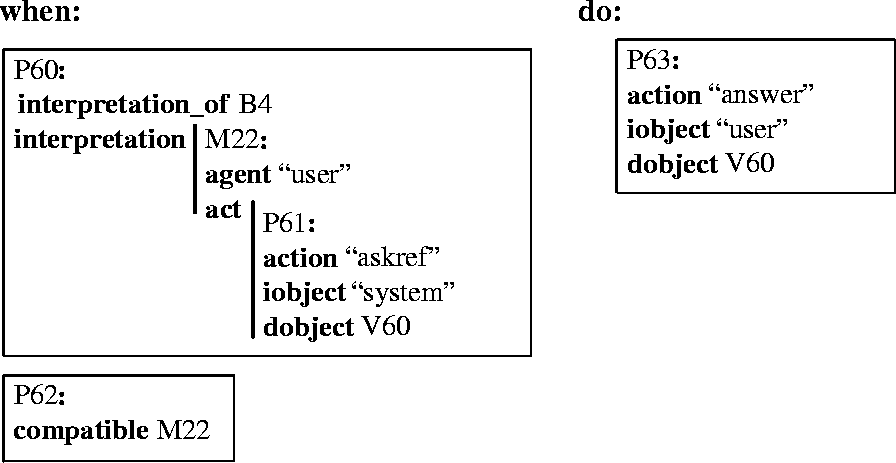
The assertion of an interpretation of the utterance as an askref and its acceptance as a coherent continuation of the dialog leads to an action by the system to answer the question.
Figure 11 is an acting rule (by contrast to the inference rules discussed previously), which glosses as: if the user asks the system a question (P60) and the system believes that it is compatible with the dialog to answer the question (P62) then do the action of answering the question. 7To achieve the latter action (answer) the system uses a plan in which the system deduces possible values of Mary's age by replacing the what in the question with a variable, and responds by saying the answer (if any). This answer is realized as a natural language expression using our real-time generator, YAG (discussed in Section 5).
Thus, any computer system that communicates must be able to cope with the possibility of miscommunication. RRM addresses possible misunderstandings (as well as expected interpretations), while respecting the time-constraints of Intelligent Dialog Systems, by combining intentional and social accounts of interaction to capture the expectations that help constrain interpretation. An action is considered a manifestation of misunderstanding if there is no coherent link apparent and there is a reason for supposing that misunderstanding has occurred.
Figure 12 shows a schema for detecting a misunderstanding (in particular a misunderstanding that is detected by the agent who has misunderstood, i.e. a self-misunderstanding [Schegloff1992]). Figure 13 shows a schema for repairing a misunderstanding (in particular, for making a repair of a self-misunderstanding after hearing an unexpected reply, i.e. a fourth-turn repair [Schegloff1992]). (For clarity of presentation, we are not showing the detailed representations corresponding to these schema; they are similar to those of section 3.2.) ColTrain uses these RRM schemata to handle misunderstandings.
Figure 12 shows the dialog discussed in Section 3.1, the schema that is used to detect a misunderstanding and the bindings that are used when matching the schema against the knowledge base. The system's interpretations of the user's utterances U1 and U2 are not compatible. Additionally, there is an alternative interpretation of U1. This allows the system to decide that its original interpretation of U1 was incorrect. In summary, this schema allows the detection of the system's misunderstanding.
Figure 13 shows the same dialog, the schema that is used to repair a misunderstanding, and the bindings that are used when matching the schema against the knowledge base. This schema allows the system to perform a repair. In this case, the system has detected that it was a mistake to provide the probability relations and that the user wanted the causality relations. The repair is the (conventionally expected) reply to a request for causality information.
The method that we describe here, which is used in our system ARGUER, uses argument schemata that match the deep meaning representation of propositions that have been advanced in a dialog. In contrast to [Birnbaum et al.1980,Vreeswijk1995,Zukerman et al.1998,Karacapilidis and Papadias1998,Alvarado1990], we use a general computational method of establishing relations between propositions. Argument schemata characterize important patterns of argument that are used to establish whether propositions support or attack other propositions. These patterns are instantiated by propositions expressed by the agents during a dialog, as well as related beliefs that the agents might hold. To account for disagreements, separate models of the agents' beliefs are maintained, both for the system and the user. Hence, a proposition believed by the system might not necessarily be believed by the user. To generate a correct and convincing response, the system considers both its own beliefs and those beliefs held by the user. In addition to allowing for incremental processing of arguments, this method is symmetric because it can be used for interpretation or generation of arguments. This is important because the system can have the role of observer or participant.
When the user inputs an utterance, the system will attempt to interpret the user's utterance as an attack or support on a prior utterance of the system. It does so by asking, What does the user's utterance attack? and second, What does the user's utterance support? All reasoning to answer these questions occurs in the user's belief model and makes use of all relevant knowledge sources therein [Ali et al.1999b]. When there is an argument, the system's response will attempt to attack some previous utterances of the user (or, failing that, provide supporting arguments to prior system utterances).
The underlying principle for detecting arguments in ARGUER is to find a general case of an argument schema into which the meaning representation of an utterance can be matched. (Argument schema can also be used to generate a rebuttal.)
The example shown in Figure 14 illustrates an argument and a schema that could be used to detect it. This schema detects that U1 is a potential attack to S1. If the system's interpretation of S1 implies a consequence that is not consistent with the system's interpretation of U1 then U1 is an attack on S1. In short, since uncontrolled high blood pressure can lead to a heart attack (which is not healthy) the user's utterance is an attack.
The use of argument schemata for argument detection and rebuttal allows argument relations between propositions to be established dynamically. Moreover, the method is incremental in that it allows processing of each piece of the utterance and uses only a part of the argument to continue.
Templates are declarative representations of text structure. Each form in a YAG template is a rule that expresses how a surface constituent should be realized, given features present in the input. YAG can accept feature structures directly, or can map propositions represented as SNePS case frames onto their feature structure equivalents and select an appropriate template for their realization. YAG's approach to realization is practical, because it's speed does not depend on the number of template types that have been defined.
|
Inputs to YAG may include multiple propositions as well as a list of control features, as shown in Figure 5. When processing this input, YAG treats the first proposition as the primary proposition to be realized. YAG will map the MEMBER-CLASS proposition to the template shown in Figure 16. The control features, form = decl and attitude = be, are also used in selecting the template. (If the form had been interrogative, a template for generating a yes-no question would have been used.)
|
width 3 in ((EVAL member) (TEMPLATE verb-form ((process "be") (person (member person)) (number (member number)) (gender (member gender))) ) (EVAL class) (PUNC "." left) ) width 3 in |
|
width 2.9 in (member-class ((decl (be (template member-class) (slot-map ((class class) (member member)) ) (feature nil) ) ))) width 2.9 in |
Prior to realization, a mapping from each type of proposition to the name of the corresponding template in a mapping table is specified. (This is the primary task in constructing a new knowledge representation realization component for other knowledge representations.) Each mapping entry provides a declarative specification for constructing a feature structure from the propositions and control features. A sample entry of a mapping table is given in Figure 17.
This research supports robust, flexible, multi-modal, mixed-initiative interaction between people and computer systems by combining techniques from language processing, knowledge representation, and human-machine communication.
This work is important because it specifies an end-to-end, declarative, computational theory that uses a uniform framework to represent the variety of knowledge that is brought to bear in collaborative interactions. Specifically: