System Overview
In the following we shortly introduce our system architecture and our graphical user interface.
Soon to come: a short video about our user simulation in action.
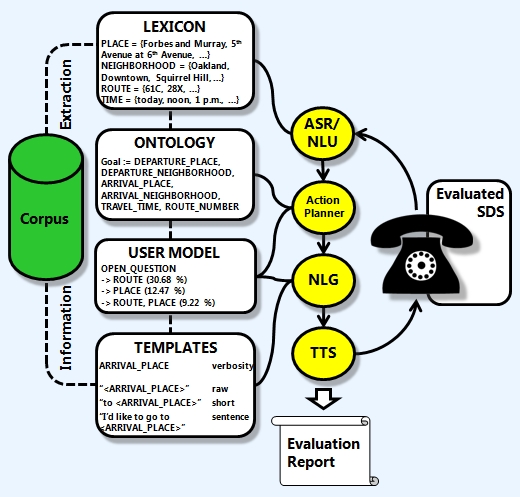 |
| SpeechEval Architecture |
The system’s architecture maintains the modular organization of most SDS, consisting of modules for
speech recognition (ASR), natural language understanding
(NLU), action planning, answer generation (NLG) and
text-to-speech synthesis (TTS). Since our simulation uses speech as
interface to the SDS a speech recognizer is the first part of
the architecture and takes as input the SDS prompt received
from the telephone line. Using speech instead of text
or intentions as the interface in the simulation has the advantage of
being more realistic and more flexible. We also do not have
to worry about introducing simulated ASR errors in our output and our
experiments show that the synthesized speech the simulation
sends to the SDS is similar in recognition rate to human input.
The following figures give a short overview of the
SpeechEval-GUI and the visualization options for the
underlying knowledge bases.
 |
| Extracted User Templates |
|
 |
| Successful Simulation |
|
 |
| Scripted Dialog Example |
|

