In languages such as Dutch and German, there are two positions in a declarative sentence where tensed verbs may appear: in second position of a main clause, and in final position of a subordinate sentences.
One possible approach would be to define specific grammar rules to represent the different possible distributions of a verb. However, this causes an unacceptable duplication in the grammar. A more elegant approach would be to use the same verb phrase rule in both subordinate and main clauses and to use a threading mechanism such that the tensed verb in a main clause is ``raised'' from an ``underlying'' sentence-final position to a surface second position (see [Netter1992] for a more detailed discussion).
In the grammar
specified in appendix A (which is an adaption of
the one presented in [VanNoord1993]) the subcategorization rule
( ![]() ) and the empty vp rule (
) and the empty vp rule ( ![]() ) realizes such an approach. In
these rules the final verb position of a subordinate clause is directly
expressed. For main clauses, it is assumed that the tensed verb in
second position also occupies the final position, but is
phonologically empty. This empty element is defined as the head
element of the verbal phrase, which ``inherits'' the subcategorization
and semantic information in the v2 position. Thus, the empty element
serves as the head of the verb phrase it is an element of, which means
that it will percolate its subcategorization information as well its
semantics up to the maximal projection. This means, that the head is
involved in a filler-gap dependency. In [Netter1992] it is also
argued for using binary structures instead of a flat
structure, e.g., to allow for insertion of modifiers. This binary branching
is expressed in the rules mentioned above and in the modifier vp rule
(
) realizes such an approach. In
these rules the final verb position of a subordinate clause is directly
expressed. For main clauses, it is assumed that the tensed verb in
second position also occupies the final position, but is
phonologically empty. This empty element is defined as the head
element of the verbal phrase, which ``inherits'' the subcategorization
and semantic information in the v2 position. Thus, the empty element
serves as the head of the verb phrase it is an element of, which means
that it will percolate its subcategorization information as well its
semantics up to the maximal projection. This means, that the head is
involved in a filler-gap dependency. In [Netter1992] it is also
argued for using binary structures instead of a flat
structure, e.g., to allow for insertion of modifiers. This binary branching
is expressed in the rules mentioned above and in the modifier vp rule
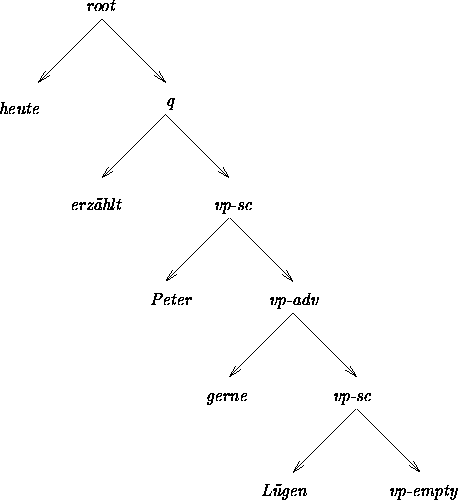
( ![]() ). Using these rules together yields the following derivation tree
for the string ``Heute erzählt Peter gerne Lügen'':
). Using these rules together yields the following derivation tree
for the string ``Heute erzählt Peter gerne Lügen'':
However, parsing and generation of constructions where such rules are involved is not a trivial task, be they top-down, bottom-up or a mixture of both. And this is true also for our uniform algorithm, if we do not spend some more effort to solve the problem. Solving this problem in the uniform approach causes some problems, because the phenomenon of verb second reveals a real asymmetrical and dual behaviour for parsing and generation.