
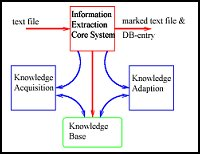
Along with the rapidly growing distribution of the Internet, the problem of information overload is beginning to take over: the more on-line texts are accessible, the more difficult it is to use this information potential constructively, i.e. to find relevant information, extract it and represent it in a compact and comprehensive manner. In the ParaDime project an intelligent system is being developed with the Saarbrücker Information Extraction System SMES to enable targeted information extraction from German on-line documents (press releases, economic reports, technical descriptions). Innovative language technology is being employed so that even complex facts can be extracted and represented in compact form. This completely new type of procedure supports content-search and indexing, allowing the extraction of such complex information as the turnover and profit development of individual companies from on-line reports. In order to keep up with the constantly changing course of events, machine learning processes are employed for the automatic configuration of SMES and to adapt them to new functions.
- SMES is an efficient core system for the intelligent retrieval of information from German documents. The prototype SMES is already used successfully in scientific and industrial projects.
- SMES manages vast sources of linguistic knowledge (amongst others a dictionary containing over 120,000 word stems and very extensive specialist grammars), and has extremely fast and robust natural language components at its disposal.
- SMES can be trained and configured for new functions with machine learning processes, while the parameters can be adapted to various text lengths and the amount of information required.
- SMES integrates graphic visualisation techniques, server architecture and access to the Internet.
 Prof. Dr. Günter Neumann
Prof. Dr. Günter Neumann
