
ICML 2025: DFKI research warns of deceptive explainability in AI systems
| Knowledge & Business Intelligence | Data Management & Analysis | Data Science and its Applications


What happens when AI systems make correct predictions but give completely different reasons for how they arrive at this result? Can users then not simply choose the explanation that best fits their desired narrative? The DFKI team led by Prof Sebastian Vollmer (Rahul Sharma, Sumantrak Mukherjee, Andrea Šipka, Eyke Hüllermeier, Sergey Redyuk and David Antony Selby) investigated precisely this problem and identified a structural risk to the trustworthiness of AI with the term X-hacking.
X-hacking: When AutoML plausibly deceives
The term X-hacking, based on the p-hacking known from statistics, describes two central mechanisms:
- Cherry-Picking: from a large number of similarly good models, the one whose explanation best supports the desired result is specifically selected.
- Directed search: AutoML systems not only optimise the prediction performance, but also specifically find models with certain explanation patterns - an often underestimated risk.
The problem is that feature importance - i.e. the weighting of input features - can differ drastically, even if the models deliver almost identically good results. This is particularly sensitive in fields of application such as medical research or social science, where explainable models often form the basis for critical decisions.
‘The explainability of a model can become an illusion, especially when there are many plausible but contradictory models to choose from.’, says David Antony Selby, researcher at Data Science and its Applications.
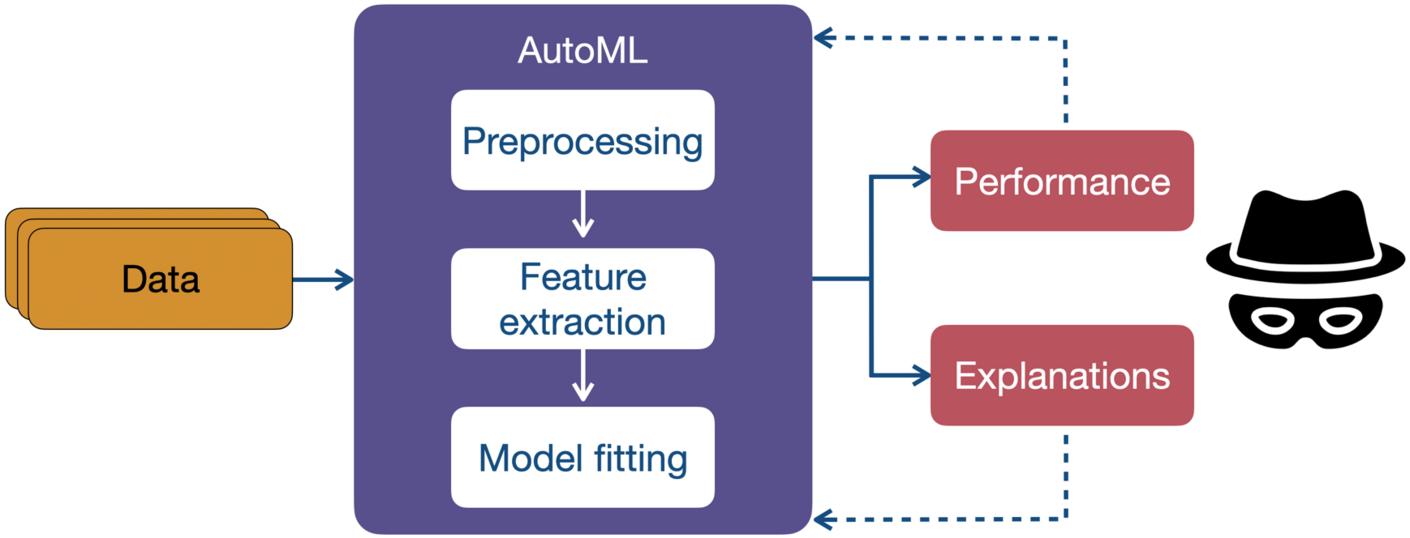
What is behind AutoML - the core of the problem?
AutoML (Automated Machine Learning) stands for automated processes for the development, selection and optimisation of ML models. Software tools take over many tasks that were previously reserved for experienced ML engineers, such as the selection of suitable model architectures, preprocessing steps and parameter tuning.
 © FB: Data Science and its Applications
© FB: Data Science and its ApplicationsEspecially in data-intensive fields such as medicine, industry or social research, AutoML tools promise faster development, lower access barriers and reproducible results. However, it is precisely this automation that makes it difficult to trace the origins of modelling decisions - a critical aspect of explainable AI. The best-known AutoML frameworks include auto-sklearn, Google Cloud AutoML, H2O.ai und Microsoft Azure AutoML.
Solution approach: Honest explainability through transparency
The DFKI team is deliberately not proposing any technical control mechanisms, but rather a scientifically reflected practice based on transparency and methodological diligence. The following recommendations take centre stage:
1. explanation histograms:
show the distribution of model explanations across all valid models and help to recognise outliers immediately.
2. complete pipeline documentation:
not only should the result be disclosed, but also the entire search space of models, data pre-processing and evaluation metrics.
3. interdisciplinary training:
Specialist disciplines using AutoML should be aware of the methodological risks and not just trust the software.
Trustworthy AI as a DFKI focus
The ICML 2025 study emphasises DFKI's research approach of making artificial intelligence not only powerful, but also transparent and socially trustworthy. In the context of the strategic focus ‘Trustworthy AI’, this work is an example of how scientific excellence and methodological responsibility can be combined.
Contact:
Prof. Dr. Sebastian Vollmer
Head research department Data Science and its Applications, DFKI
- Sebastian.Vollmer@dfki.de
- Phone: +49 631 20575 7601
Press contact:
Further information:
- Paper: X-Hacking: The Threat of Misguided AutoML
ICML version on openreview; authors: Rahul Sharma, Sumantrak Mukherjee, Andrea Sipka, Eyke Hüllermeier, Sebastian Josef Vollmer, Sergey Redyuk, David Antony Selby
- Poster X-Hacking: The Threat of Misguided AutoML
Presentation: Wed 16 Jul 4:30 p.m. PDT — 7 p.m. PDT East Exhibition Hall A-B #E-1109