
ICML 2025: DFKI-Forschung warnt vor trügerischer Erklärbarkeit in KI-Systemen
| Wissen & Business Intelligence | Data Management & Analysis | Data Science und Ihre Anwendungen


„In einer Zeit, in der KI Entscheidungen erklärt, aber nicht immer versteht, müssen wir als Wissenschaft Verantwortung für die Tiefe dieser Erklärungen übernehmen – und für ihre Grenzen.“
Was passiert, wenn KI-Systeme zwar korrekte Vorhersagen treffen, aber völlig unterschiedlich begründen, wie sie zu diesem Ergebnis kommen? Können sich Nutzende dann nicht einfach diejenige Erklärung aussuchen, die am besten zu ihrem gewünschten Narrativ passt? Genau diese Problematik untersuchte das DFKI-Team um Prof. Sebastian Vollmer (Rahul Sharma, Sumantrak Mukherjee, Andrea Šipka, Eyke Hüllermeier, Sergey Redyuk und David Antony Selby), und identifizierte mit dem Begriff X-Hacking ein strukturelles Risiko für die Vertrauenswürdigkeit von KI.
X-Hacking: Wenn AutoML plausibel täuscht
Der Begriff X-Hacking, in Anlehnung an das aus der Statistik bekannte p-Hacking, beschreibt zwei zentrale Mechanismen:
- Cherry-Picking: Aus einer Vielzahl ähnlich guter Modelle wird gezielt dasjenige ausgewählt, dessen Erklärung das gewünschte Ergebnis am besten unterstützt.
- Gerichtete Suche: AutoML-Systeme optimieren nicht nur die Vorhersageleistung, sondern finden auch gezielt Modelle mit bestimmten Erklärungsmustern – ein oft unterschätztes Risiko.
Das Problem: Die sogenannte Feature-Importance – also die Gewichtung von Eingabemerkmalen – kann sich drastisch unterscheiden, selbst wenn die Modelle nahezu identisch gute Ergebnisse liefern. Besonders sensibel ist das in Anwendungsfeldern wie der medizinischen Forschung oder der Sozialwissenschaft, wo erklärbare Modelle oft die Grundlage für kritische Entscheidungen bilden.
„Die Erklärbarkeit eines Modells kann zur Illusion werden, besonders wenn viele plausible, aber widersprüchliche Modelle zur Auswahl stehen", sagt David Antony Selby, Wissenschaftler im Forschungsbereich Data Science and its Applications am DFKI.
Was steckt hinter AutoML – dem Kern der Problematik?
AutoML (Automated Machine Learning) steht für automatisierte Verfahren zur Entwicklung, Auswahl und Optimierung von ML-Modellen. Dabei übernehmen Softwaretools viele Aufgaben, die zuvor erfahrenen ML-Ingenieur*innen vorbehalten waren: etwa die Wahl geeigneter Modellarchitekturen, Preprocessing-Schritte und Parameter-Tuning.
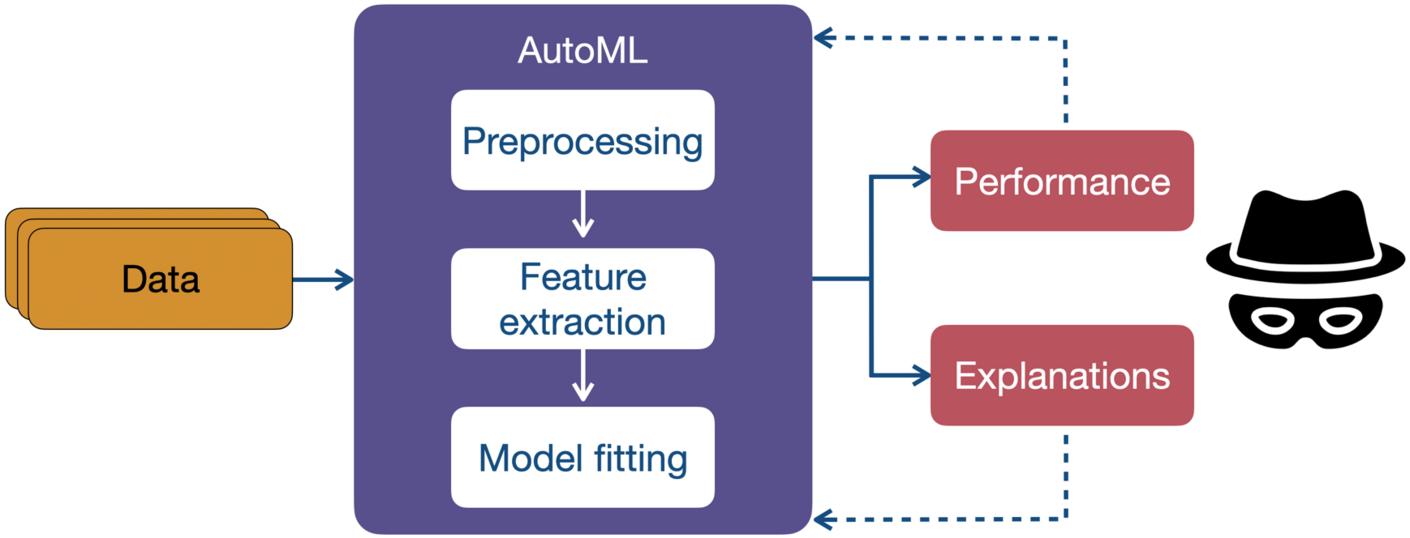
Besonders in datenintensiven Feldern wie Medizin, Industrie oder Sozialforschung versprechen AutoML-Tools schnellere Entwicklung, niedrigere Zugangshürden und reproduzierbare Ergebnisse. Doch gerade diese Automatisierung macht es schwer, die Entstehung von Modellentscheidungen nachzuvollziehen – ein kritischer Punkt bei erklärbarer KI. Zu den bekanntesten AutoML-Frameworks zählen auto-sklearn, Google Cloud AutoML, H2O.ai und Microsoft Azure AutoML.
Lösungsansatz: Ehrliche Erklärbarkeit durch Transparenz
Das DFKI-Team schlägt bewusst keine technischen Kotnrollmechanismen vor, sondern eine wissenschaftlich reflektierte Praxis, die auf Transparenz und methodischer Sorgfalt basiert. Deir Empfehlungen stehen dabei im Mittelpunkt:
1. Explanation Histograms:
Zeigen die Verteilung der Modell-Erklärungen über alle validen Modelle und helfen, Ausreißer sofort zu erkennen.
2. Vollständige Pipeline-Dokumentation:
Offengelegt werden sollte nicht nur das Ergebnis, sondern der gesamte Suchraum an Modellen, Datenvorverarbeitung und Bewertungsmetriken.
3. Interdisziplinäre Ausbildung:
Fachdisziplinen, die AutoML nutzen, sollten sich der methodischen Risiken bewusst sein und nicht nur der Software vertrauen.
„Ziel ist eine Wissenschaftskultur, die nicht nur auf Genauigkeit, sondern auch auf Ehrlichkeit in der Erklärbarkeit setzt.“
Trustworthy AI als DFKI-Fokus
Die Studie zur ICML 2025 unterstreicht den Forschungsansatz des DFKI, Künstliche Intelligenz nicht nur leistungsstark, sondern auch transparent und gesellschaftlich vertrauenswürdig zu gestalten. Im Kontext des strategischen Schwerpunkts „Trustworthy AI“ zeigt diese Arbeit exemplarisch, wie wissenschaftliche Exzellenz und methodische Verantwortung zusammengedacht werden können.
Kontakt:
Prof. Dr. Sebastian Vollmer
Leiter Forschungsbereich Data Science and its Applications, DFKI
- Sebastian.Vollmer@dfki.de
- Tel.: +49 631 20575 7601
Pressekontakt:
Weitere Informationen:
- Paper: X-Hacking: The Threat of Misguided AutoML
ICML version on openreview; authors: Rahul Sharma, Sumantrak Mukherjee, Andrea Sipka, Eyke Hüllermeier, Sebastian Josef Vollmer, Sergey Redyuk, David Antony Selby
- Poster X-Hacking: The Threat of Misguided AutoML
Presentation: Wed 16 Jul 4:30 p.m. PDT — 7 p.m. PDT East Exhibition Hall A-B #E-1109